

The abilities of deep learning are fascinating, just as this Paschke arch CC by David DeHetre
One of the successful insights to training neural networks has been the rectified linear unit, or short the ReLU, as a fast alternative to the traditional activation functions such as the sigmoid or the tanh. One of the major advantages of the simle ReLu is that it does not saturate at the upper end, thus the network is able to distinguish a poor answer from a really poor answer and correct accordingly.

A schematic of the PReLU. The LReLU has the same schematic with the only difference being the α being a constant. Curtesy PReLU article.
A modification to the ReLU, the Leaky ReLU, that would not saturate in the opposite direction has been tested but did not help. Interestingly in a recent paper by the Microsoft© deep learning team, He et al. revisited the subject and introduced a Parametric ReLU, the PReLU, achieving superhuman performance on the imagenet. The PReLU learns the parameter α (alpha) and adjusts it through basic gradient descent.
In this tutorial I will benchmark a few different implementations of the ReLU and PReLU together with Theano. The benchmark test will be on the MNIST database, mostly for convenience.
Why Theano
Coming from an R environment I tried to find a good deep learning alternative in R. Unfortunately the graphics card integration is often lacking and it seems that the other alternatives are much further along. I chose Theano as this is one of the most popular packages and it compiles everything at the back-end for speed. There are several packages that build upon Theano but I figured it was just as well to learn something from the core.
Possible ReLU and PReLU implementations
I’ve come across a few different ReLU implementations:
def ReLU1(X):
return T.maximum(X, 0.)
def ReLU2(X):
return T.switch(X < 0., 0., X)
def ReLU3(X):
return ((X + abs(X)) / 2.0)
# See Jan Schlüter's comment
def ReLU3v2(X):
return (0.5 * (X + abs(X)))
def ReLU4(X):
return X * (X > 0)
def ReLU5(X):
return (T.sgn(X) + 1) * X * 0.5
The only one that is slightly less intuitive is the third one where the the absolute causes the value to cancel out while the positive values are divided by one half. For obvious reasons only the ReLU2 and ReLU3 are possible to adapt to a PReLU version:
def PReLU2(X, alpha):
return T.switch(X < 0, alpha * X, X)
def PReLU3(X, alpha):
pos = ((X + abs(X)) / 2.0)
neg = alpha * ((X - abs(X)) / 2.0)
return pos + neg
# See Jan Schlüter's comment
def PReLU3v2(X, alpha):
pos = 0.5 * (1 + alpha)
neg = 0.5 * (1 - alpha)
return pos * X + neg * abs(X)
Note that this also requires the alpha parameters for the PReLU set. These need to correspond to the number of activations in the corresponding layer and be included in the update function – here’s an abstract of the PReLU test function that takes care of this. Note the calculations of the input sizes and how they relate as this is crucial for setting the correct alpha shapes:
# Input size from MNIST: 28 x 28 pixels # First filter gives (28 + 3 - 1, 28 + 3 -1) = (30, 30) # - note the full border alternative # The maxpool (2,2) gives (15, 15) # The output is thus (32, 15, 15) product = 7200 w1 = init_weights((32, 1, 3, 3)) # Second filter gives (15 - 3 + 1, 15 - 3 + 1) = (13, 13) # The maxpool (2,2) gives (7, 7) # - note that maxpool has ignore_border = False by default # The output is thus (64, 7, 7) product = 3136 w2 = init_weights((64, 32, 3, 3)) # Third filter gives (7 - 3 + 1, 7 - 3 + 1) = (5, 5) # The maxpool (2,2) gives (3, 3) # The output is thus (128, 3, 3) product = 1152 w3 = init_weights((128, 64, 3, 3)) # Note that the 3 is not the filter size above w4 = init_weights((128 * 3 * 3, 625)) # The fully connected layer sizes are rather straight forward w_o = init_weights((625, 10)) alpha1 = theano.shared(np.ones((30,), dtype=theano.config.floatX)*.5) alpha2 = theano.shared(np.ones((13,), dtype=theano.config.floatX)*.5) alpha3 = theano.shared(np.ones((5,), dtype=theano.config.floatX)*.3) alpha4 = theano.shared(np.ones((625,), dtype=theano.config.floatX)*.1) params = [w1, w2, w3, w4, w_o, # Note the addition of the alpha to the update alpha1, alpha2, alpha3, alpha4] updates = RMSprop(cost, params, lr=0.001)
Setting up the MNIST
I rely on the excellent tutorial by Alec Radford for loading the MNIST database:
from load import mnist trX, teX, trY, teY = mnist(onehot=True) trX = trX.reshape(-1, 1, 28, 28) teX = teX.reshape(-1, 1, 28, 28)
As the MNIST is almost too easy we’ll limit the dataset to 1/6 of the original size:
# Reduce the sample in order to make the problem a little harder select = np.random.choice(trX.shape[0], 10000, replace=False) trX = trX[select,:] trY = trY[select,:]
The basic ReLU benchmark functions
The network is identical to that of Alec’s original net that attains about 99.5% accuracy on the full dataset after 30 epochs.
def runModelTraining(epochs, train, predict, alpha1 = None, alpha2 = None, alpha3 = None, alpha4 = None): block_size = 128 i = 0 top_accuracy = 0 start_time = time.time() duration = [] accuracy = [] while i < epochs: i = i + 1 for start in range(0, trY.shape[0], block_size): end = start + block_size if (end > trY.shape[0]): end = trY.shape[0] train(trX[start:end], trY[start:end]) # Print basic output print "** Run no. {0} **".format(i) duration.append(getDuration(start_time)) accuracy.append(testAccuracy(test_x=teX, test_y=teY, predict_fn=predict)) print "With a {accuracy:.2f}% accuracy".format(accuracy= accuracy[len(accuracy) - 1]* 100) # For the alphas we want to make sure that they learn something if (not alpha1 == None): print "The alpha values are for " +\ " no. 1: {alpha1:.2f}, no. 2: {alpha2:.2f}".format(alpha1 = np.mean(alpha1.get_value()), alpha2 = np.mean(alpha2.get_value())) + \ " no. 3: {alpha3:.2f} , no. 4: {alpha4:.2f}".format(alpha3 = np.mean(alpha3.get_value()), alpha4 = np.mean(alpha4.get_value())) return duration, accuracy def ReLU_eval(activator, epochs = no_epochs): # Create tensor variables that will be used in the models X = T.ftensor4() Y = T.fmatrix() # Input size from MNIST: 28 x 28 pixels # First filter gives (28 + 3 - 1, 28 + 3 -1) = (30, 30) # - note the full border alternative # The maxpool (2,2) gives (15, 15) # The output is thus (32, 15, 15) product = 7200 w1 = init_weights((32, 1, 3, 3)) # Second filter gives (15 - 3 + 1, 15 - 3 + 1) = (13, 13) # The maxpool (2,2) gives (7, 7) # - note that maxpool has ignore_border = False by default # The output is thus (64, 7, 7) product = 3136 w2 = init_weights((64, 32, 3, 3)) # Third filter gives (7 - 3 + 1, 7 - 3 + 1) = (5, 5) # The maxpool (2,2) gives (3, 3) # The output is thus (128, 3, 3) product = 1152 w3 = init_weights((128, 64, 3, 3)) # Note that the 3 is not the filter size above w4 = init_weights((128 * 3 * 3, 625)) # The fully connected layer sizes are rather straight forward w_o = init_weights((625, 10)) def basic_model(X, w1, w2, w3, w4, w_o, p_drop_conv, p_drop_hidden, activator): l1a = activator(conv2d(X, w1, border_mode='full')) l1 = max_pool_2d(l1a, (2, 2)) l1 = dropout(l1, p_drop_conv) l2a = activator(conv2d(l1, w2)) l2 = max_pool_2d(l2a, (2, 2)) l2 = dropout(l2, p_drop_conv) l3a = activator(conv2d(l2, w3)) l3b = max_pool_2d(l3a, (2, 2)) l3 = T.flatten(l3b, outdim=2) l3 = dropout(l3, p_drop_conv) l4 = activator(T.dot(l3, w4)) l4 = dropout(l4, p_drop_hidden) pyx = softmax(T.dot(l4, w_o)) return pyx noise_py_x = basic_model(X = X, w1 = w1, w2 = w2, w3 = w3, w4 = w4, w_o = w_o, p_drop_conv = 0.2, p_drop_hidden = 0.5, activator = activator) py_x = basic_model(X = X, w1 = w1, w2 = w2, w3 = w3, w4 = w4, w_o = w_o, p_drop_conv = 0., p_drop_hidden = 0., activator = activator) y_x = T.argmax(py_x, axis=1) cost = T.mean(T.nnet.categorical_crossentropy(noise_py_x, Y)) params = [w1, w2, w3, w4, w_o] updates = RMSprop(cost, params, lr=0.001) train = theano.function(inputs=[X, Y], outputs=cost, updates=updates, allow_input_downcast=True) predict = theano.function(inputs=[X], outputs=y_x, allow_input_downcast=True) duration, accuracy = runModelTraining(epochs, train, predict) return duration, accuracy
The PReLU training is identical with a few small exceptions:
def PReLU_eval(activator, epochs = no_epochs): # Create tensor variables that will be used in the models X = T.ftensor4() Y = T.fmatrix() # Input size from MNIST: 28 x 28 pixels # First filter gives (28 + 3 - 1, 28 + 3 -1) = (30, 30) # - note the full border alternative # The maxpool (2,2) gives (15, 15) # The output is thus (32, 15, 15) product = 7200 w1 = init_weights((32, 1, 3, 3)) # Second filter gives (15 - 3 + 1, 15 - 3 + 1) = (13, 13) # The maxpool (2,2) gives (7, 7) # - note that maxpool has ignore_border = False by default # The output is thus (64, 7, 7) product = 3136 w2 = init_weights((64, 32, 3, 3)) # Third filter gives (7 - 3 + 1, 7 - 3 + 1) = (5, 5) # The maxpool (2,2) gives (3, 3) # The output is thus (128, 3, 3) product = 1152 w3 = init_weights((128, 64, 3, 3)) # Note that the 3 is not the filter size above w4 = init_weights((128 * 3 * 3, 625)) # The fully connected layer sizes are rather straight forward w_o = init_weights((625, 10)) alpha1 = theano.shared(np.ones((30,), dtype=theano.config.floatX)*.5) # @UndefinedVariable alpha2 = theano.shared(np.ones((13,), dtype=theano.config.floatX)*.5) # @UndefinedVariable alpha3 = theano.shared(np.ones((5,), dtype=theano.config.floatX)*.3) # @UndefinedVariable alpha4 = theano.shared(np.ones((625,), dtype=theano.config.floatX)*.1) # @UndefinedVariable def basic_model(X, w1, w2, w3, w4, w_o, alpha1, alpha2, alpha3, alpha4, p_drop_conv, p_drop_hidden, activator): l1a = activator(conv2d(X, w1, border_mode='full'), alpha1) l1 = max_pool_2d(l1a, (2, 2)) l1 = dropout(l1, p_drop_conv) l2a = activator(conv2d(l1, w2), alpha2) l2 = max_pool_2d(l2a, (2, 2)) l2 = dropout(l2, p_drop_conv) l3a = activator(conv2d(l2, w3), alpha3) l3b = max_pool_2d(l3a, (2, 2)) l3 = T.flatten(l3b, outdim=2) l3 = dropout(l3, p_drop_conv) l4 = activator(T.dot(l3, w4), alpha4) l4 = dropout(l4, p_drop_hidden) pyx = softmax(T.dot(l4, w_o)) return pyx noise_py_x = basic_model(X = X, w1 = w1, w2 = w2, w3 = w3, w4 = w4, w_o = w_o, alpha1 = alpha1, alpha2 = alpha2, alpha3 = alpha3, alpha4 = alpha4, p_drop_conv = 0.2, p_drop_hidden = 0.5, activator = activator) py_x = basic_model(X = X, w1 = w1, w2 = w2, w3 = w3, w4 = w4, w_o = w_o, alpha1 = alpha1, alpha2 = alpha2, alpha3 = alpha3, alpha4 = alpha4, p_drop_conv = 0., p_drop_hidden = 0., activator = activator) y_x = T.argmax(py_x, axis=1) cost = T.mean(T.nnet.categorical_crossentropy(noise_py_x, Y)) params = [w1, w2, w3, w4, w_o, # Note the addition of the alpha to the update alpha1, alpha2, alpha3, alpha4] updates = RMSprop(cost, params, lr=0.001) train = theano.function(inputs=[X, Y], outputs=cost, updates=updates, allow_input_downcast=True) predict = theano.function(inputs=[X], outputs=y_x, allow_input_downcast=True) duration, accuracy = runModelTraining(epochs, train, predict, alpha1 = alpha1, alpha2 = alpha2, alpha3 = alpha3, alpha4 = alpha4) return duration, accuracy
Results and conclusions
My three main conclusions are:
- The maximum and the absolute calculations seem to have performed equally fast.
- The added time using PReLU is minimal.
- Similarly the added precision is minimal, although PReLU seems to slightly faster find the sweet-spot.
The latter point is hard to really on due to the limited complexity of the MNIST database, I would expect that PReLU comes in handy when dealing with more complex tasks.
Using some R-code I created a few plots illustrating the above conclusions (after some googling and getting an error when installing the python ggplot I gave up):
fn <- file.choose() df <- read.csv(fn) library(reshape) df <- melt(df, id.vars = "epochs") df$grp <- df$variable lvl <- levels(df$grp) lvl[grep("1", lvl)] <- "Maximum" lvl[grep("[^v]2", lvl)] <- "Switch" lvl[grep("3v2", lvl)] <- "Absolute v2" lvl[grep("3$", lvl)] <- "Absolute v1" lvl[grep("4", lvl)] <- "Greater" lvl[grep("5", lvl)] <- "Sign" levels(df$grp) <- lvl df % group_by(grp, dur, epochs) %>% summarise(max = max(value), min = min(value), ratio = max/min) -> sum_df library(ggplot2) dur_df % group_by(Type, epochs) %>% summarise(avg = mean(value)) png(filename = "PReLU_duration_benchmark.png", width = 600*2, height = 400*2, res = 126) ggplot(dur_df, aes(x = grp, y = value, fill = Type)) + geom_bar(stat="identity", position = "dodge") + scale_x_discrete(labels = dur_df$grp) + scale_fill_brewer(type = "qual", palette = 4) + xlab("Type of calcualtion") + ylab("Time (min) at 30 epochs") + theme_bw() + geom_text(aes(x = grp, label = ifelse(ratio == 1, "", sprintf("PReLU / ReLU\n%.0f%%", ratio * 100)), y = max*.8, fill = NULL), data = subset(sum_df, epochs == 30 & dur == "Duration"), angle = 35, size = 5) + theme(text = element_text(size = 18)) dev.off() acc_df <- subset(df, dur == "Accuracy") acc_df %<>% group_by(Type, epochs) %>% summarise(avg = mean(value)) png(filename = "PReLU_acc_benchmark.png", width = 600*2, height = 400*2, res = 126) ggplot(acc_df, aes(x = epochs, y = avg, col = Type)) + geom_line(lwd = 2) + scale_y_continuous(lim = c(.8, 1), expand = c(0,0)) + scale_x_continuous(lim = c(1, 30), expand = c(0,0), breaks = seq(5, 30, by=5)) + scale_color_brewer(type = "qual", palette = 4) + guides(linetype = guide_legend(title = "Calc.")) + xlab("Epochs") + ylab("Accuracy") + theme_bw() + theme(text = element_text(size = 18)) dev.off()
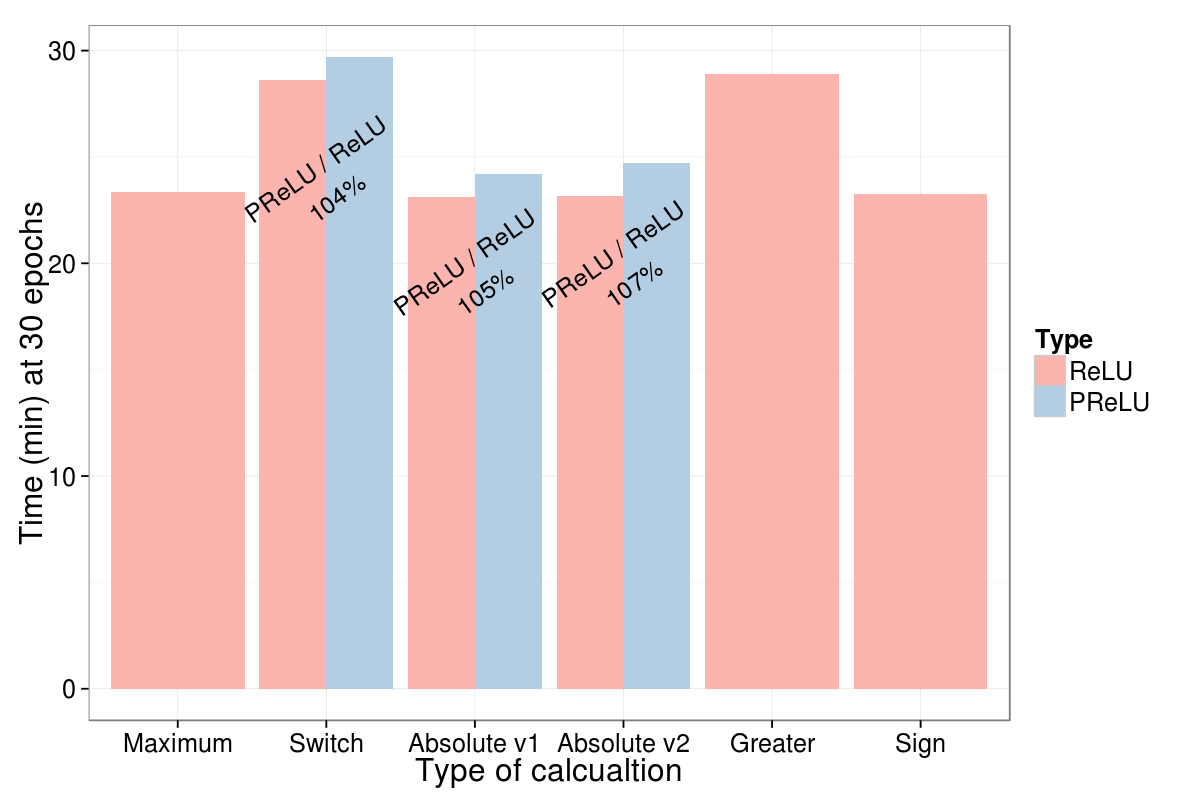
Bar chart comparing the ReLUs and PReLUs time at the end of 30 epochs
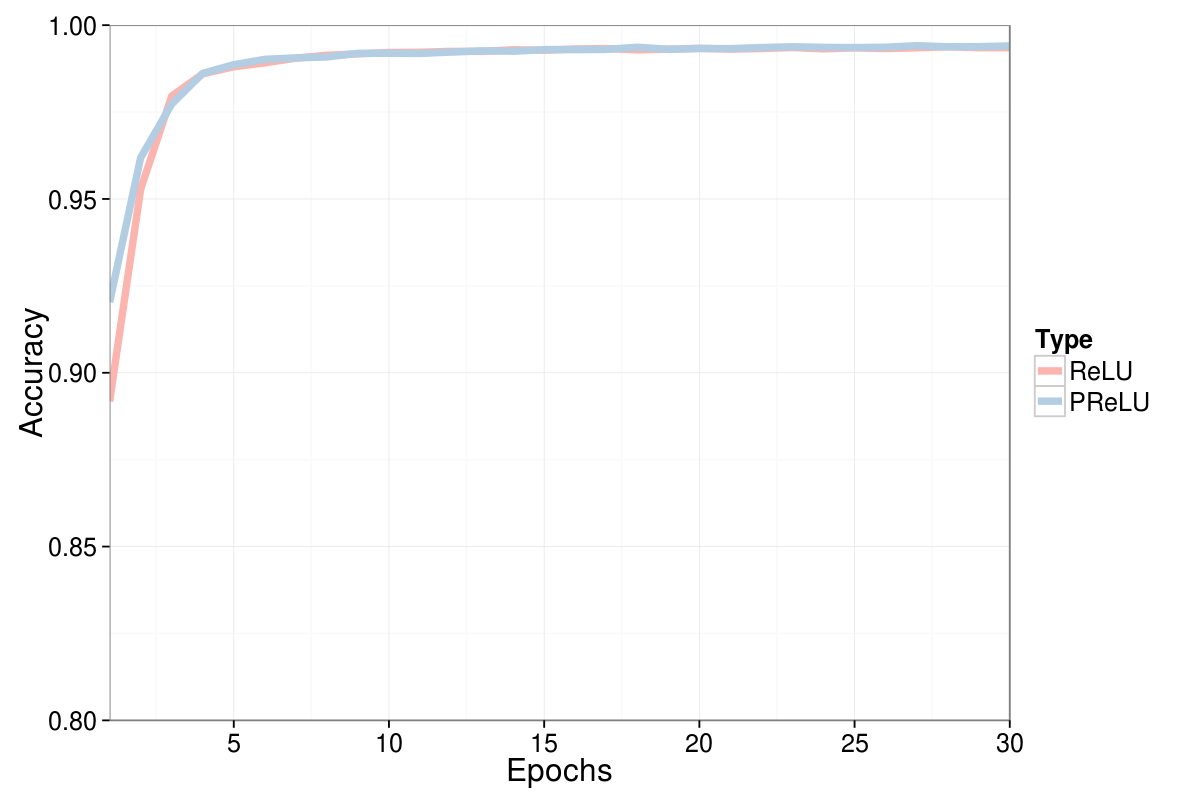
A line chart illustrating the lack of difference in accuracy between the methods
The α values
Interestingly the α (alpha) values behaved in a similar fashion to that in the original article, alphas in the lower layers were higher compared to lower layers. Here’s a shortened sample from the PReLU3 print:
Testing PReLU3 ** Run no. 1 ** It took 7.7seconds With a 12.29% accuracy The alpha values are for no. 1: 0.50, no. 2: 0.50 no. 3: 0.30 , no. 4: 0.10 ** Run no. 2 ** It took 17.8seconds With a 25.59% accuracy The alpha values are for no. 1: 0.50, no. 2: 0.50 no. 3: 0.30 , no. 4: 0.10 ** Run no. 3 ** It took 27.9seconds With a 21.56% accuracy The alpha values are for no. 1: 0.50, no. 2: 0.50 no. 3: 0.30 , no. 4: 0.10 ** Run no. 4 ** It took 38.0seconds With a 9.81% accuracy The alpha values are for no. 1: 0.50, no. 2: 0.50 no. 3: 0.30 , no. 4: 0.10 ** Run no. 5 ** It took 48.1seconds With a 43.79% accuracy The alpha values are for no. 1: 0.50, no. 2: 0.50 no. 3: 0.33 , no. 4: 0.10 ** Run no. 6 ** It took 58.2seconds With a 81.48% accuracy The alpha values are for no. 1: 0.51, no. 2: 0.52 no. 3: 0.36 , no. 4: 0.11 ** Run no. 7 ** It took 1.0min, 8.3seconds With a 93.87% accuracy The alpha values are for no. 1: 0.52, no. 2: 0.53 no. 3: 0.37 , no. 4: 0.11 ** Run no. 8 ** It took 1.0min, 18.4seconds With a 94.96% accuracy The alpha values are for no. 1: 0.53, no. 2: 0.53 no. 3: 0.37 , no. 4: 0.11 ** Run no. 9 ** It took 1.0min, 28.5seconds With a 96.49% accuracy The alpha values are for no. 1: 0.53, no. 2: 0.54 no. 3: 0.37 , no. 4: 0.11 ** Run no. 10 ** It took 1.0min, 38.6seconds With a 96.63% accuracy The alpha values are for no. 1: 0.54, no. 2: 0.54 no. 3: 0.37 , no. 4: 0.10 .... ** Run no. 15 ** It took 2.0min, 29.1seconds With a 97.67% accuracy The alpha values are for no. 1: 0.55, no. 2: 0.54 no. 3: 0.36 , no. 4: 0.10 .... ** Run no. 20 ** It took 3.0min, 19.6seconds With a 98.16% accuracy The alpha values are for no. 1: 0.56, no. 2: 0.54 no. 3: 0.35 , no. 4: 0.09 .... ** Run no. 25 ** It took 4.0min, 10.1seconds With a 98.04% accuracy The alpha values are for no. 1: 0.57, no. 2: 0.54 no. 3: 0.34 , no. 4: 0.09 ** Run no. 26 ** It took 4.0min, 20.2seconds With a 97.95% accuracy The alpha values are for no. 1: 0.57, no. 2: 0.54 no. 3: 0.34 , no. 4: 0.09 ** Run no. 27 ** It took 4.0min, 30.3seconds With a 98.37% accuracy The alpha values are for no. 1: 0.57, no. 2: 0.54 no. 3: 0.35 , no. 4: 0.09 ** Run no. 28 ** It took 4.0min, 40.4seconds With a 98.45% accuracy The alpha values are for no. 1: 0.57, no. 2: 0.54 no. 3: 0.35 , no. 4: 0.09 ** Run no. 29 ** It took 4.0min, 50.5seconds With a 98.43% accuracy The alpha values are for no. 1: 0.58, no. 2: 0.54 no. 3: 0.35 , no. 4: 0.09 ** Run no. 30 ** It took 5.0min, 0.6seconds With a 98.32% accuracy The alpha values are for no. 1: 0.58, no. 2: 0.54 no. 3: 0.34 , no. 4: 0.09
Deriving the ReLU/PReLU
Part of the speed impacting the implementation is the derivative. From what I understand this is something that Theano does in the background using the grad-function:
import theano from theano import tensor as T from theano import pp x = T.dscalar('x') y = x ** 2 pp(T.grad(y, x))
Give the somewhat harder to read 2 * x:
((fill((x ** TensorConstant{2}), TensorConstant{1.0}) * TensorConstant{2}) *
(x ** (TensorConstant{2} - TensorConstant{1})))
Using the same approach for the maximum function gives:
y = T.maximum(x, 0) pp(T.grad(y, x))
It is readable but hardly intuitive that the meaning is x > 0 ? 1 : 0:
(eq(maximum(x, TensorConstant{0}), x) *
fill(maximum(x, TensorConstant{0}), TensorConstant{1.0}))
The absolute calculation ((x + abs(x)) / 2.0) gives the rather mindnumming that I think reduces to (1 / 2 + 1 / 2 * x / |x|):
((fill(((x + |x|) / TensorConstant{2.0}), TensorConstant{1.0}) /
TensorConstant{2.0}) +
(((fill(((x + |x|) / TensorConstant{2.0}), TensorConstant{1.0}) /
TensorConstant{2.0}) * x) /
|x|))
And if your want to get a real headache, here’s the PReLU winner and it’s two derivatives:
alpha = T.dscalar('alpha') pos = ((x + abs(x)) / 2.0) neg = alpha * ((x - abs(x)) / 2.0) y = neg + pos print(pp(T.grad(y, x))) print("\n") print(pp(T.grad(y, alpha)))
I haven’t even tried to deduce the elements… not sure I can even find x > 0 ? 1 : α in this mess…
(((((fill(((\alpha * ((x - |x|) / TensorConstant{2.0})) +
((x + |x|) / TensorConstant{2.0})),
TensorConstant{1.0}) *
\alpha) / TensorConstant{2.0}) +
(((-((fill(((\alpha * ((x - |x|) / TensorConstant{2.0})) +
((x + |x|) / TensorConstant{2.0})),
TensorConstant{1.0}) *
\alpha) / TensorConstant{2.0})) *
x) / |x|)) +
(fill(((\alpha * ((x - |x|) / TensorConstant{2.0})) +
((x + |x|) / TensorConstant{2.0})),
TensorConstant{1.0}) / TensorConstant{2.0})) +
(((fill(((\alpha * ((x - |x|) / TensorConstant{2.0})) +
((x + |x|) / TensorConstant{2.0})),
TensorConstant{1.0}) / TensorConstant{2.0}) *
x) / |x|))
(fill(((\alpha * ((x - |x|) / TensorConstant{2.0})) +
((x + |x|) / TensorConstant{2.0})),
TensorConstant{1.0}) *
((x - |x|) / TensorConstant{2.0}))
Using Jan Schlüter’s approach
As Jan Schlüter points out the correct way of analyzing the output is through the debugprint method. Unfortunately, I find it not that much easier to read:
# define forward expression
relu = T.maximum(x, 0.)
# define backward expression
out = T.matrix('out')
grelu = theano.grad(None, x, known_grads={relu: out})
# compile backward expression
fgrelu = theano.function([x, out], grelu)
# optional: print graph
from theano.printing import debugprint
print "Original graph:"
debugprint(grelu)
print "\nOptimized graph:"
debugprint(fgrelu)
Original graph:
Elemwise{mul} [@A] ''
|Elemwise{EQ} [@B] ''
| |Elemwise{maximum} [@C] ''
| | |x [@D]
| | |DimShuffle{x,x} [@E] ''
| | |TensorConstant{0.0} [@F]
| |x [@D]
|out [@G]
Optimized graph:
HostFromGpu [@A] '' 5
|GpuElemwise{Mul}[(0, 0)] [@B] '' 4
|GpuElemwise{Composite{Cast{float32}(EQ(i0, i1))}}[(0, 0)] [@C] '' 3
| |GpuElemwise{maximum,no_inplace} [@D] '' 2
| | |GpuFromHost [@E] '' 1
| | | |x [@F]
| | |CudaNdarrayConstant{[[ 0.]]} [@G]
| |GpuFromHost [@E] '' 1
|GpuFromHost [@H] '' 0
|out [@I]
The switch-variant:
Original graph:
Elemwise{add,no_inplace} [@A] ''
|Elemwise{second,no_inplace} [@B] ''
| |x [@C]
| |DimShuffle{x,x} [@D] ''
| |TensorConstant{0.0} [@E]
|Elemwise{Switch} [@F] ''
|Elemwise{lt,no_inplace} [@G] ''
| |x [@C]
| |DimShuffle{x,x} [@H] ''
| |TensorConstant{0.0} [@E]
|DimShuffle{x,x} [@I] ''
| |TensorConstant{0.0} [@E]
|out [@J]
Optimized graph:
HostFromGpu [@A] '' 4
|GpuElemwise{Switch}[(0, 0)] [@B] '' 3
|GpuElemwise{Composite{Cast{float32}(LT(i0, i1))}}[(0, 0)] [@C] '' 2
| |GpuFromHost [@D] '' 1
| | |x [@E]
| |CudaNdarrayConstant{[[ 0.]]} [@F]
|CudaNdarrayConstant{[[ 0.]]} [@F]
|GpuFromHost [@G] '' 0
|out [@H]
The absolute variant 1:
Original graph:
Elemwise{add,no_inplace} [@A] ''
|Elemwise{true_div} [@B] ''
| |out [@C]
| |DimShuffle{x,x} [@D] ''
| |TensorConstant{2.0} [@E]
|Elemwise{true_div} [@F] ''
|Elemwise{mul} [@G] ''
| |Elemwise{true_div} [@B] ''
| |x [@H]
|Elemwise{Abs} [@I] ''
|x [@H]
Optimized graph:
HostFromGpu [@A] '' 3
|GpuElemwise{Composite{((i0 * i1) + (i0 * i1 * sgn(i2)))}}[(0, 1)] [@B] '' 2
|CudaNdarrayConstant{[[ 0.5]]} [@C]
|GpuFromHost [@D] '' 1
| |out [@E]
|GpuFromHost [@F] '' 0
|x [@G]
The absolute variant 2:
Original graph:
Elemwise{add,no_inplace} [@A] ''
|Elemwise{mul} [@B] ''
| |out [@C]
| |DimShuffle{x,x} [@D] ''
| |TensorConstant{0.5} [@E]
|Elemwise{true_div} [@F] ''
|Elemwise{mul} [@G] ''
| |Elemwise{mul} [@B] ''
| |x [@H]
|Elemwise{Abs} [@I] ''
|x [@H]
Optimized graph:
HostFromGpu [@A] '' 3
|GpuElemwise{Composite{((i0 * i1) + (i0 * i1 * sgn(i2)))}}[(0, 1)] [@B] '' 2
|CudaNdarrayConstant{[[ 0.5]]} [@C]
|GpuFromHost [@D] '' 1
| |out [@E]
|GpuFromHost [@F] '' 0
|x [@G]
Environment
The benchmark was performed on a cuDNN-enabled K40c GPU together with Theano 0.7 and Ubuntu 14.04.
Hey, nice post, but there are two traps you’ve fallen into as a new Theano user.
1. If you want to benchmark the performance of the rectifier nonlinearity itself (whether leaky/parameterized or not), timing a full network may introduce too much uncertainty. Theano provides a way to profile its operations, though, and you can use that to profile just the forward pass or just the backward pass (gradient) of the activation function, as I did here: https://github.com/Lasagne/Lasagne/pull/163#issuecomment-85635041
2. Your printout of the symbolic expressions is more complicated than what’s computed by Theano. On compiling a function, several graph optimizers modify the expression to be simpler or more numerically stable. So instead, you should compile a function computing the expression and use theano.printing.debugprint on it. In the github issue linked above, I show how to do that as well.
Besides, your PReLU3 expression can be further simplified, as I’ve done here: https://github.com/Lasagne/Lasagne/commit/ab0fef321f98823e37d9250c044ed907d8996f91
Feel free to amend your post or link to the discussion on github!
Cheers, Jan
Thanks for the feedback! Sorry for not getting back earlier but I’ve had a lot to take care of before I could rerun the code with your input. I’ve added your variant and also a little debugprint output. Should probably spend more time looking at exactly on how to interpret the debugprint, but it is nice to at least know of the correct Theano way to look at the end result.
I’m also glad that the discussion regarding adding a default ReLU-implementation to Theano has taken off. I’m aware of the problem when benchmarking in a full network, this has been my playground for learning the basics and the benchmark addition was just something I did when trying to figure out how to implement the PReLU.
Best
Max
Pingback: Debug a deep Neural Networks | Keunwoo Choi